1. 정의 및 설명
매크로 함수 (Macro Function)
- 정의: 전처리기(Preprocessor) 지시문인 #define을 사용하여 정의하는 함수이다.
- 동작: 컴파일 전 단계(전처리 단계)에서 코드 내의 매크로 이름을 단순 텍스트 치환 방식으로 코드 본문으로 바꾼다.
- 특징: 자료형(Type)을 확인하지 않으며, 단순한 문자열 대치이므로 괄호 처리를 잘못하면 연산 순서 오류나 부작용(Side Effect)이 발생하기 쉽다.

장점 : 함수가 인라인화 되어 성능의 향상으로 이어질 수 있다.
단점 : 함수의 정의 방식이 일반함수에 비해서 복잡하다. 복잡한 함수의 정의에는 한계가 있다.
인라인 함수 (Inline Function)
- 정의: 함수 선언 앞에 inline 키워드를 붙여 정의하는 함수이다
- 동작: 컴파일러(Compiler)가 처리한다. 함수를 호출하는 대신 함수 본문의 코드를 호출 지점에 삽입하도록 컴파일러에게 요청한다.
- 특징: 일반 함수처럼 매개변수의 자료형 검사(Type Checking)를 수행하며, 디버깅이 쉽고 안전하다. (단, 코드가 너무 길거나 복잡하면 컴파일러가 인라인화를 거부하고 일반 함수로 처리할 수도 있다.)

키워드 inline 선언은 컴파일러에 의해서 처리된다.
컴파일러가 함수의 인라인화를 결정한다.
inline 선언이 되어도 인라인처리 되지 않을 수 있고, inline 선언이 없어도 인라인처리 될 수 있다.

매크로 함수의 장점은 취하고 단점은 보완한 것이 C++의 인라인 함수이다.
2. 인라인 함수에는 없는 매크로 함수만의 장점
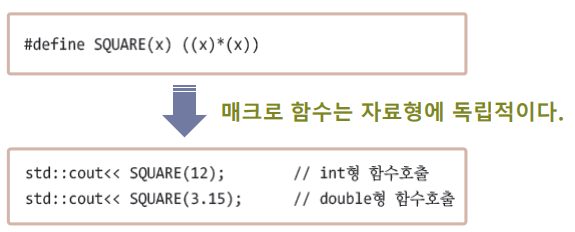
inline 선언된 함수를 위의 형태로 호출하려면, 각 자료형 별로 함수가 오버로딩 되어야 한다.
즉, 매크로 함수와 달리 자료형에 독립적이지 못하다.

3. 매크로 함수 주의사항

위 코드에는 치명적인 문제가 있다.
매크로 함수의 단순 치환으로 인한 연산 순서 오류를 조심해야 한다.
cout << SQ(9 + 5) << '\n'; // 우리가 기대하는 계산은 (9 + 5)^2, 즉 14 x 14 = 196
하지만 매크로는 단순 글자 바꾸기이다.
컴파일러는 이 코드를 전처리 단계에서 아래와 같이 바꿉니다.
- 매크로 정의: #define SQ(x) x * x
- 입력된 값: x 자리에 9 + 5라는 글자가 그대로 들어감.
- 실제 변환된 코드: 9 + 5 * 9 + 5 = 59 <- 우리가 예상했던 답인 196과 다름
그럼 어떻게 해야할까?
// 올바른 매크로 정의 (괄호 필수!)
#define SQ(x) ((x) * (x))
다음과 같이 함수를 정의하면 된다.
주의할 점: 매크로 함수를 만들 때 매개변수 x를 괄호로 감싸지 않으면 9+5 같은 수식이 들어왔을 때 연산자 우선순위가 엉켜서 엉뚱한 값(59)이 나온다.
해결책: 매크로 함수를 쓸 때는 무조건 모든 인자에 괄호를 쳐야 한다. (하지만 더 좋은 건 inline 함수를 쓰는 것이다.)
4. 인라인 함수의 단점
1. 인라인 함수의 구현을 짧게 1~3줄 정도의 짧은 코드로 작성한다. (길면 캐시 적중률이 감소한다.)
2. 구현이 길어진다면 컴파일러는 인라인 함수를 일반 함수로 취급하게 된다.
3. 인라인 함수를 자주 사용하면, 같은 코드의 중복으로 바이너리 실행 파일이 커진다.
4. 인라인 함수가 변경된다면, 전체 코드가 그 변경사항을 반영해야 하므로, 컴파일 시간 오버헤드가 발생한다.
5. 컴파일러가 인라인 함수를 무시하는 경우
1. 함수에 루프가 포함되어 있을 때 (for, while, do-while)
2. 함수에 정적 변수들이 있을 때 (static variables)
3. 함수가 재귀호출을 할 때
4. 함수가 switch나 goto문이 포함될 때
6. 인라인 함수와 매크로 함수 비교

1. 매크로 함수 MAX(x++, y++)의 경우
결과: x=11, y=22, m=21
매크로는 전처리기에 의해 코드가 다음과 같이 단순 치환된다.
// #define MAX(A,B) (A>B)?A:B
m = (x++ > y++) ? x++ : y++;
이 코드가 실행되는 순서를 따라가 보자 (초기값: x=10, y=20)
- 조건 비교 (x++ > y++):
- x(10)와 y(20)를 비교 10 > 20은 거짓(False)
- 비교가 끝난 직후, 후위 연산자(++)가 동작하여 x는 11, y는 21
- 삼항 연산자 선택:
- 조건이 거짓이므로 뒤의 항인 뒤의 y++이 선택되어 실행
- 결과 도출 (y++):
- 현재 y는 아까 21이 되었다. 이 21 값을 m에 대입한다. (m = 21)
- 대입 후, 다시 후위 연산자(++)가 동작하여 y는 22가 된다.
결론: y에 붙은 ++가 비교할 때 한 번, 선택되었을 때 또 한 번 실행되어 총 두 번 증가(y=22)하게 된 것이다. 이것이 매크로의 치명적인 부작용(Side Effect)이다.
2. 인라인 함수 max(x++, y++)의 경우
결과: x=11, y=21, m=20
인라인 함수는 아무리 코드가 삽입된다고 해도 함수이다. 함수 호출의 원칙(Call by Value)을 철저히 지킨다.
inline int max(int a, int b) { ... }
이 코드가 실행되는 순서 (초기값: x=10, y=20)
- 매개변수 전달 (Argument Evaluation):
- 함수를 호출하기 전에 인자값을 먼저 확정 짓는다.
- max(x++, y++)를 호출할 때:
- 첫 번째 인자: 10을 넘기고, x는 11.
- 두 번째 인자: 20을 넘기고, y는 21
- 즉, 함수 내부로 들어가는 값은 a=10, b=20 이다.
- 함수 내부 실행:
- if (a > b) -> if (10 > 20) -> 거짓(False).
- return b; -> 20을 반환
- 결과 도출:
- 반환된 값 20이 m에 대입된다. (m = 20)
결론: 함수 호출 시점에 ++ 연산이 딱 한 번만 깔끔하게 처리되고, 그 값만 함수로 전달되었기 때문에 상식적인 결과가 나온다.
요약: 왜 값이 다를까?
| 구분 | 매크로 MAX | 인라인 함수 max |
| 핵심 차이 | 코드를 복사해서 ++ 연산자가 두 번 등장함 | 값을 계산해서 넘기므로 ++가 한 번만 실행됨 |
| y의 값 | 비교할 때 +1, 반환할 때 +1 → 총 +2 증가 (22) | 호출할 때 +1 → 총 +1 증가 (21) |
| m의 값 | 두 번째 증가하기 전의 값 (21) | 호출 시점의 값 (20) |
'tech > C++' 카테고리의 다른 글
| [C++] 접근제어 지시자 (0) | 2025.12.07 |
|---|---|
| [C++] call by value와 call by reference (0) | 2025.12.07 |
| [C++] 참조자를 선언할 때 잘못되게 선언되는 것 (0) | 2025.12.07 |