요즘 많은 부트캠프들에서 그리고 사이드 프로젝트를 하면서 redis를 많이 쓰곤 한다.
정작 redis에 대해서 정말 잘 알고 쓰는 거일까? 라는 생각이 들었다.
대답은 아니요 이다.
많은 사람들 뿐만 아니라 나 또한 redis를 왜 쓰는지 redis는 어떻게 동작하는지 알고 쓰지는 않았던 거 같다.
이러한 지난 날을 반성하고 redis가 무엇인지 정확히 알고자 이 해체 분석기 시리즈를 작성하기로 마음먹었다.
1. Redis 넌 도대체 누구냐
Redis(Remote Dictionary Server)는 오픈소스 기반의 인메모리 데이터 구조 저장소이다. 모든 데이터를 RAM(메모리)에 저장하여 디스크 I/O 없이 초고속 데이터 접근을 제공한다. 일반 관계형 데이터베이스가 아닌 Key-Value 구조의 NoSQL DBMS로서, 데이터베이스, 캐시, 메시지 브로커 등 다양한 용도로 활용된다.
2. Redis의 핵심 아키텍처
1. 메모리 계층과 Redis의 위치
컴퓨터 메모리는 계층 구조로 이루어져 있다.
- L1/L2 캐시: CPU에 가장 가깝고 가장 빠름 (나노초 단위)
- L3 캐시: 중간 속도
- 메인 메모리(RAM): Redis가 데이터를 저장하는 공간 (마이크로초 단위)
- SSD/디스크: 느리지만 용량이 큼 (밀리초 단위)
Redis가 극도로 빠른 이유는 데이터를 L1/L2 캐시와 메인 메모리 수준에 저장하기 때문이다.
2. 싱글 스레드 설계와 이벤트 루프
Redis는 싱글 스레드 기반으로 동작하지만, 이것이 약점이 아닌 강점이다.
구성: 메인 스레드 1개 + 보조 스레드 3개 (총 4개)
- 클라이언트 명령 처리는 싱글 스레드로 수행
- 커널 I/O 레벨에서는 멀티플렉싱(Multiplexing)으로 동시 처리
while(true) {
if (클라이언트A의 응답 준비 완료) → A의 결과 처리
else if (클라이언트B의 새 요청 들어옴) → B의 요청 처리
else if (클라이언트C의 응답 준비 완료) → C에게 결과 전송
...
}
장점:
- 원자적 연산: 중간에 다른 명령이 끼어들 수 없음
- 동시성 문제 완전 회피: 뮤텍스, 세마포어 등의 복잡한 동기화 불필요
- 높은 동시성: 여러 클라이언트의 요청을 효율적으로 처리
3. RESP 프로토콜 (클라이언트-서버 통신)
Redis는 RESP(Redis Serialization Protocol)를 사용하여 클라이언트와 TCP로 통신한다.
RESP의 특징:
- 텍스트 기반: 사람이 읽을 수 있는 형식
- 간단한 구현: 파싱이 빠름
- 효율적: 바이너리 프로토콜 수준의 성능
통신 흐름:
- 클라이언트가 RESP 형식의 명령어를 TCP 소켓으로 전송
- 서버가 명령어 처리
- 서버가 RESP 형식의 응답 반환
- Pipelining 지원: 여러 명령어를 한 번에 전송 가능

3. Redis의 5가지 핵심 데이터 구조
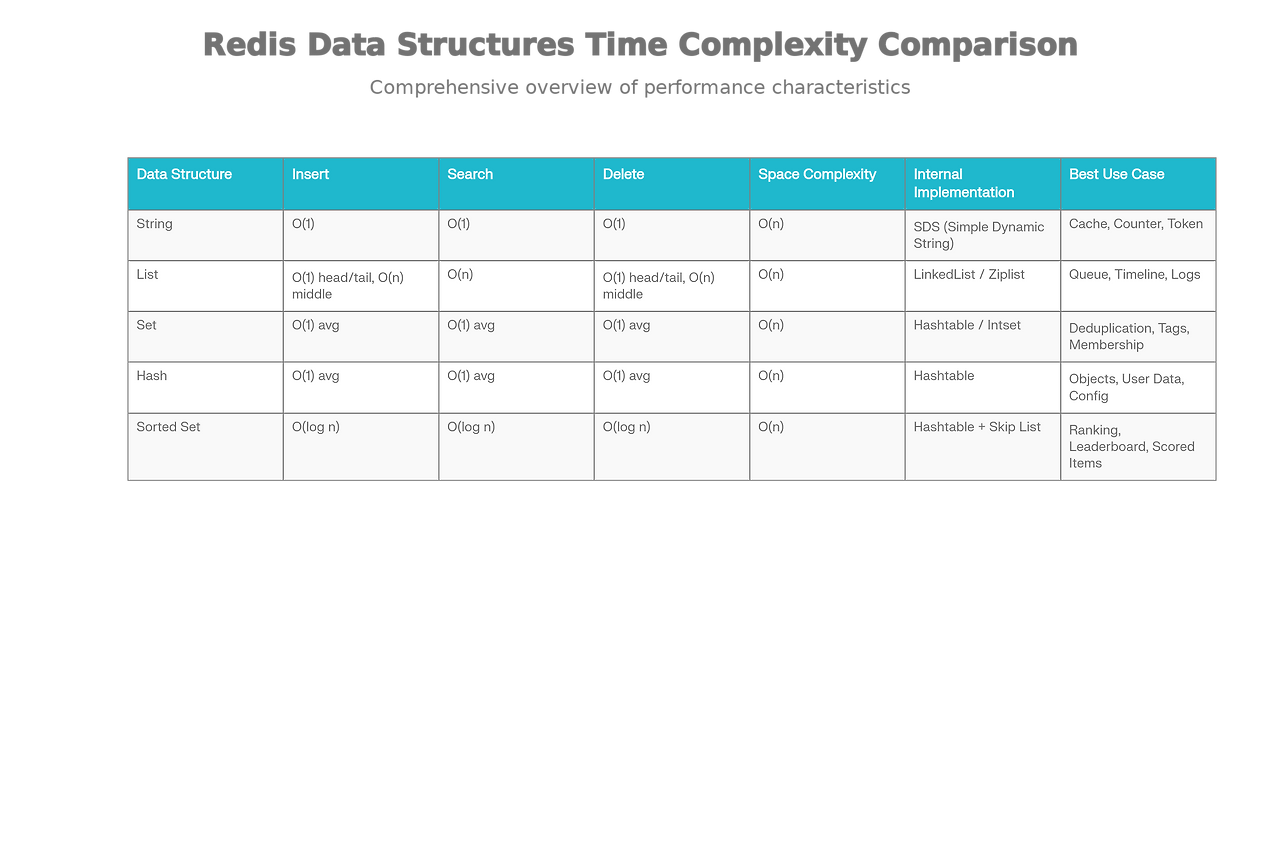
1. String (문자열)
내부 구현: SDS(Simple Dynamic String)
단순 텍스트뿐 아니라 JSON, 숫자, 직렬화된 객체도 저장 가능
주요 명령어:
- SET, GET: 저장/조회
- INCR, DECR: 원자적 증감
- APPEND, STRLEN: 문자열 조작
시간복잡도: O(1)
사용 사례: 캐시, 세션, 카운터, 토큰 저장
2. List (리스트)
내부 구현: Linked List (소량 데이터는 Ziplist 사용)
순서가 있는 문자열 목록으로, 양 끝(head/tail)에서의 추가/제거가 매우 빠름
주요 명령어:
- LPUSH, RPUSH: 양 끝에 추가 - O(1)
- LPOP, RPOP: 양 끝에서 제거 - O(1)
- LRANGE: 범위 조회 - O(N)
- BLPOP, BRPOP: 블로킹 팝 (메시지 큐용)
사용 사례: 작업 큐, 메시지 대기열, 최근 N개 데이터, Timeline
3. Set (집합)
내부 구현: Hashtable (정수 집합은 Intset)
중복을 허용하지 않는 비정렬 집합 실무에서 자동 중복 제거가 매우 유용
주요 명령어:
- SADD: 멤버 추가 - O(1)
- SREM: 멤버 제거 - O(1)
- SMEMBERS: 모든 멤버 조회 - O(N)
- SINTER, SUNION, SDIFF: 집합 연산
사용 사례: 중복 방지, 온라인 유저 추적, 좋아요, 태깅
4. Hash (해시)
내부 구현: Hashtable (필드-값 쌍)
객체 형태의 구조화된 데이터를 효율적으로 저장합니다.
주요 명령어:
- HSET, HGET: 필드 저장/조회 - O(1)
- HGETALL: 모든 필드-값 조회 - O(N)
- HINCRBY: 필드 값 증감
- HEXISTS: 필드 존재 여부 확인
메모리 효율성: String 타입 2개보다 Hash 1개로 15~30% 메모리 절감 가능
사용 사례: 사용자 정보 캐싱, 상품 속성, 설정값 저장
5. Sorted Set (정렬된 집합)
내부 구현: Hashtable + Skip List
각 멤버에 점수(score)를 할당하여 점수 기준으로 자동 정렬
Skip List 최적화:
- 데이터가 소량(기본값 128개)일 때는 Ziplist 사용
- 데이터 증가 시 자동으로 Skip List로 변환
- 시간복잡도: O(log N) 검색, O(log N) 삽입/삭제
주요 명령어:
- ZADD: 멤버와 점수 추가 - O(log N)
- ZRANGE, ZREVRANGE: 범위 조회 - O(log N + M)
- ZRANK: 순위 조회 - O(log N)
- ZINCRBY: 점수 증감
사용 사례: 게임 랭킹, 실시간 리더보드, 인기 검색어, 추천 시스템
이렇게 오늘은 간단하게 redis에 대해서 맛을 보았다.
앞으로 redis 인스턴스에 대한 분리를 고려할 때 생각할 부분들에 대해서 다루면서 그 때 고민해야할 redis의 구조적인 부분들을 알아볼
생각이다.
물론 나같은 학생 수준이나 1인 개발자들은 redis를 단일 인스턴스로 띄울 것이다. (비용 이슈로 인해)
그리고 사실 엔터프라이즈 급이 아닌 이상 굳이 인스턴스를 나누는 것은 얻는 이익보다 손해가 더 클 것이라고 생각한다.
하지만 우리가 누군가가 왜 redis를 싱글 인스턴스로 띄우셨나요 했을 때 비용 때문에요 하고 끝낼 것인가?
인스턴스를 분리할 돈은 없더라고 했을 때의 장점 그리고 비용 때문에 분리를 못했다면 그 안에서 어떻게 최적화를 위한 튜닝을 하려는
노력을 했는지는 직접해보고 말할 수 있어야 한다고 생각한다.
그러기 위해서 이 시리즈를 시작했다.
나도 이제 공부하는 입장이고 간혹 틀릴 수도 있긴 하다.
그렇다면 댓글로 지적해주시면 정말 감사하겠다.